知识库问答
前面讲的 阅读辅助 是一篇 PDF 一篇 PDF 聊。但如果你已经攒了几十上百篇文献,想问"我这批文献里,谁谈到了 XXX?"——一篇篇翻就太慢了。
知识库问答就是解决这个:把一整个分类(几十、几百篇论文)一次性"喂"给 AI,之后你用中文/英文随便问,AI 读完相关片段再回答,并且告诉你引用的是哪几篇。
一句话
阅读辅助 = 和一篇 PDF 聊 · 知识库问答 = 和一整个分类(一批文献)聊。
一、先理解:什么是 RAG?(30 秒版)
知识库底层用的是 RAG(检索增强生成)。流程:
- 建索引(一次性):AI4Paper 把你这个分类下每篇文献的 PDF 正文切成一小段一小段("片段"),转成向量存到本地数据库
- 你问问题:比如"AIGC 对生产力的影响有哪些实证证据"
- 语义检索:AI4Paper 从刚才的向量库里找出最相关的几段(可能来自 3-5 篇不同的论文)
- AI 读片段再回答:把找到的片段 + 你的问题一起扔给主 AI,它只基于这些片段回答,并给出引用标注
好处:
- 不会胡编(只用检索到的片段,不凭"我猜")
- 每个结论都能追溯到原文位置,点一下就能定位到 PDF 的对应条目
- 比一篇一篇问快 10 倍
二、界面总览
打开知识库问答窗口长这样:
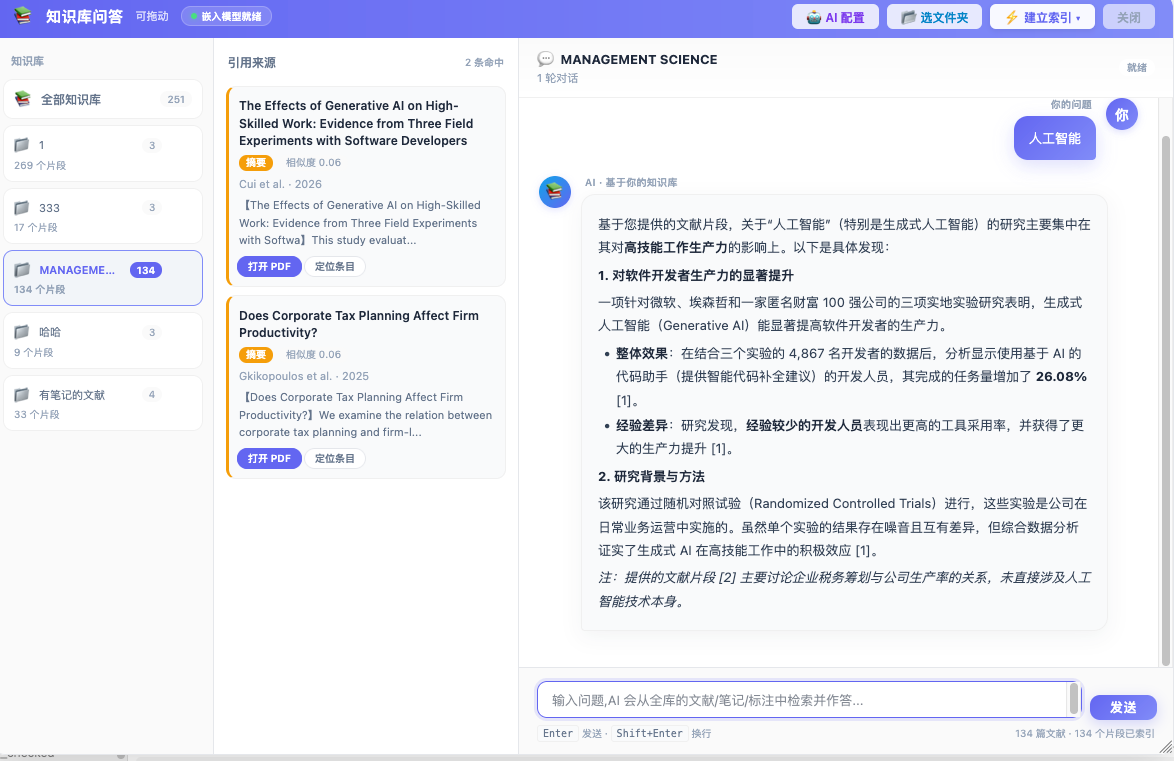
三栏结构:
2.1 左栏 · 知识库列表
一个 Zotero 分类 = 一个知识库。图上这台机器有 5 个:
| 知识库 | 已索引片段数 |
|---|---|
| 全部知识库 | 251(所有知识库合并查询) |
1 | 269 个片段 |
333 | 17 个片段 |
MANAGEME...(当前选中) | 134 个片段 |
哈哈 | 9 个片段 |
有笔记的文献 | 33 个片段 |
点一个就切换到那个知识库提问。想跨库一起问就点"全部知识库"。
2.2 中栏 · 引用来源
AI 每次回答后,用到哪些文献片段都在这里列出来——图上这次答案用了 2 篇:
- The Effects of Generative AI on High-Skilled Work(摘要,相似度 0.06)
- Does Corporate Tax Planning Affect Firm Productivity?(摘要,相似度 0.06)
每条下面两个按钮:
- 打开 PDF → 直接跳到 Zotero 阅读器打开这篇
- 定位条目 → 跳到 Zotero 文库里选中这篇
验证 AI 回答真伪的利器:它说的每一点你都能点进原文核对。
"相似度 0.06" 是好是坏?
这是向量距离,数值越小越相关(不是越大越相关)。0.06 属于非常相关。超过 0.3 一般就有点远了。
2.3 右栏 · 对话区
就是和 ChatGPT 差不多的聊天框:
- 顶部:当前知识库名(图上是
MANAGEMENT SCIENCE)+ 对话轮数 + 就绪状态 - 消息流:你的问题 / AI 回答(带 Markdown 格式、编号引用
[1][2]对应中栏来源) - 底部输入框:输入问题,
Enter发送 ·Shift+Enter换行 - 右下角状态栏:
134 篇文献 · 134 个片段已索引
2.4 顶部工具栏
- 🤖 AI 配置:切换这次问答用哪个模型(继承主 AI,也可以临时换)
- 📁 选文件夹:在知识库之间切换(和左栏等价)
- ⚡ 建立索引:首次对分类建库、或者分类里新加了文献后重建/增量
- 关闭:关窗口
三、使用流程:从零到第一次问答
3.1 准备一个分类
先在 Zotero 里有一个你真正想深问的分类——比如前面 领域新文监控 拉下来的 MANAGEMENT SCIENCE 有 134 篇论文,就是天然的知识库素材。
知识库至少要有 PDF
纯元数据(标题+摘要)也能索引,但最好的效果是有 PDF 全文。先用**下载附件(多源)**把 PDF 抓全,再建索引。
3.2 打开知识库问答
顶部工具栏点 📚 知识库 按钮(文献工作台 里讲过的那 5 个蓝色按钮之一)→ 弹出图上的窗口。
3.3 首次索引
- 左栏选你的分类(或点顶部 📁 选文件夹 挑)
- 点 ⚡ 建立索引
- 后台开始给这个分类每篇文献的 PDF 正文做分片 + 向量化
- 时间开销:100 篇文献大约 1-5 分钟(取决于你的嵌入模型服务商和文献大小)
- 首次建完,之后问答秒级响应,不用再等
嵌入模型就是做这一步向量化的模型。详见 配置 AI 服务 → 嵌入模型。
3.4 提问
索引建好后,右栏输入问题。比如:
人工智能对生产力的影响有什么实证证据?这 134 篇里哪几篇用了 RCT 实验设计?作者们对 AIGC 的负面影响有什么担忧?列一下被引次数最多的 5 篇
AI 会:
- 从索引里先检索相关片段
- 把片段 + 你的问题扔给主 AI
- 按 Markdown 格式回答,每个结论带
[1][2]这样的编号 - 中栏同步显示这几个编号对应的原文片段
3.5 追问和深挖
- 继续在对话里追问,AI 记得上下文
- 想看原文 → 点中栏的"打开 PDF"
- 怀疑 AI 说得不对 → 点"定位条目"去 Zotero 核对
- 换个知识库接着问 → 左栏切换
四、多知识库管理
一个 Zotero 用户通常会同时维护几个知识库:
| 分类 / 知识库 | 用途 |
|---|---|
MANAGEMENT SCIENCE(手动期刊监控) | 跟某本顶刊的所有论文对话 |
AIGC 教师倦怠(AI 推荐监控) | 聚焦某个研究方向 |
我的出版物 | 自己发表过的论文库 |
综述-XXX 课题 | 为写某个综述专门攒的 50 篇 |
全部知识库 | 不知道在哪个库 / 想跨库找时 |
每个库单独索引、单独问答,互不干扰。每次新增了一批文献后,点 ⚡ 建立索引 增量更新就行(只新索引加进来的片段,不会全部重来)。
五、典型场景
5.1 开题调研
100 篇文献一起问"有哪些研究的空白点还没被覆盖?",AI 在全库里交叉检索,比自己翻效率高 10 倍。
5.2 找 gap
"列出作者们提到的"未来研究方向""——AI 能把不同论文 Discussion 章节的 Limitations / Future Work 汇总出来,写 proposal 直接能用。
5.3 写综述
先问思路("主要研究方法有几类"),再问论据("用 XXX 方法的代表性论文是哪几篇"),最后汇总到笔记里。比对着 Zotero 一篇篇翻高效得多。
5.4 论文答辩备稿
临答辩前问自己这个领域的经典论文,AI 基于你攒的知识库回答——专属于你课题的"补刀"。
六、FAQ
Q1: 为啥建立索引一直转圈不完?
A: 可能原因按概率排序:
- PDF 没下全:知识库索引的是 PDF 正文,没 PDF 的只能索引标题+摘要。先右键分类→**下载附件(多源)**把 PDF 补齐
- 嵌入模型没配对:设置页的嵌入模型默认「跟随主 AI」,但某些主 AI 不带嵌入接口。去 AI 服务配置 单独给嵌入填一个(阿里
text-embedding-v3、OpenAItext-embedding-3-small都行) - 网络问题:嵌入走的是你选的服务商的 API,走不通就会一直转。换个网络 / VPN
Q2: 能问中文问题吗?英文文献也能答?
A: 能。中文提问 + 英文文献 + 中文回答 是最常见组合。向量检索对跨语言友好,大多数主流嵌入模型都支持。
Q3: AI 回答里出现"文献 [2] 主要讨论 XXX, 与本问题无直接关系"咋回事?
A: 图上就有这种情况——这其实是好事。说明 AI 没被"硬塞进来"的低相关片段带偏,而是明确告诉你这一段其实没用。RAG 系统诚实的表现。
Q4: 知识库数据存哪?隐私安全吗?
A:
- 向量索引:存在你本机 Zotero 数据目录下的 SQLite 库里,不上传云端
- 每次问答:问题 + 检索到的片段会发给主 AI(OpenAI / 通义 / DeepSeek / 本地 Ollama……看你配置)。完全离线的话用 Ollama + 本地嵌入模型
- PDF 原文始终在本地,不走云
Q5: 建一次索引消耗多少钱?
A: 嵌入比主 AI 便宜一个数量级。100 篇平均 15 页的文献,总片段数约 3000 个,用阿里 text-embedding-v3 总成本 ¥0.01 左右。基本可忽略。
Q6: 我删了文献/改了文献,知识库会自动更新吗?
A: 不会自动。**手动点一下「建立索引」**即可增量处理(它能识别哪些是新/改的)。
Q7: "全部知识库 251" 是啥意思?
A: 所有知识库合并。跨库查询时用。不知道答案在哪个分类里就用它。
读文献侧到这里就齐了:阅读辅助(逐篇精读)+ 知识库问答(整批扫一遍)覆盖 95% 的论文阅读场景。
写综述的时候,知识库配合 专业综述与研究发现 用最爽——基于你这批文献直接出带引用的综述报告。